
The Spectral Maximal Update Parameterization in Theory and Practice - December 2025
Kyle R. Chickering - kyrochickering@gmail.com
Work Completed while author was affiliated with UC Davis LUKA Lab & MBZUAI Institute of Foundation Models
[ Homepage ]
Last updated: 02.15.26
Table of Contents
Introduction
The maximal parameterization update (P) (Yang et al. 2022) has proven itself a valuable tool for reducing pre-training costs at scale. Beyond enabling learning rate transfer across model scales, P improves training dynamics by ensuring that learning occurs at the same rate across disparate layers. For large-scale training runs a correct P implementation could save millions of dollars in compute. For researchers and engineers, correctly implementing P reduces the dimensionality of hyperparameter sweeps and produces more reliable results by getting models closer to compute optimal. Additionally, P eliminates a common pitfall in the literature where two models are compared but only one model is hyperparameter tuned, which can lead to misleading or downright incorrect conclusions about model scaling and behavior.
P is not merely a theoretical consideration. During training under the standard parameterization different layers learn at different rates, effectively freezing the embeddings during training and wasting compute on sub-optimal weight updates. When using P for large networks we can attain lower losses by ensuring all layers learn at the correct rate. P also helps reduce tuning costs when preparing for large-scale training runs. By enabling zero-shot hyperparameter transfer (see the figure below) we can cheaply tune small models and avoid the expensive extrapolation and validation steps required to find the optimal hyperparmeters for large models.
This blog post is not a comprehensive introduction or tutorial on P; we assume that the reader has some familiarity with P, either through reading or attempting to read the Tensor Programs V paper (TP-V) (Yang et al. 2022) or through a resource like Dey’s Practitioner’s Guide to P (Dey et al. 2024). This blog post is intended for audiences who want a practical tool-kit for applying P, and who don’t have time to sort through the developments in the literature over the past several years. In particular we want to extend the practitioner’s toolkit so that they can implement P models which go beyond the original width-based models studied by Yang. The development of P now spans nearly half a decade and involves challenging mathematics, rendering much of the theory difficult to access. We view this as unfortunate, and believe that the mathematics and understanding yielded by P are extremely valuable for ML practitioners. To increase the understanding and awareness of P we present a heuristic approach to P derivations, based largely on the more recent “spectral perspective” of P (Yang et al. 2023b).
We argue that this later approach is better suited for understanding and deriving P. The original P formulation is derived by studying the updates of the weight matrices through constraints on the outputs of the the matrix multiply. Spectral P instead directly constrains the weight matrices themselves. This will also allow us to directly derive P scalings for depth. Additionally, the original P formulation admits a subtle failure mode where all of the conditions for feature learning are satisfied but learning rate transfer does not occur (see below). Spectral P prevents this failure mode from occurring.
From a practitioner’s perspective, having conditions directly on the weight matrices instead of on the layer outputs allows us to directly understand and debug P implementations, instead of trying to intuit the behavior of matrices by looking only at the outputs to each layer.
We strive to present a distillation of the mathematical theory and as such many of our results are not rigorous. However rigorous statements for our results can be found scattered throughout the literature.
Throughout we discuss practical insights that we have learned through the process of deriving, implementing, and debugging P. We hope that this guide can serve as a valuable resource for practitioners moving forward in implementing P, and we advocate for using either P or Muon for large scale training moving forwards.
Contributions
In this blog post we:
- Argue that the spectral conditions for feature learning, originally derived in (Yang et al. 2023b), should form the basis of our understanding of P.
- Provide a set of heuristics based on random matrix theory and Tensor Programs which allow P to be applied in contexts beyond the original derivation.
- Briefly discuss whether or not learning rate and weight decay can be transferred across batch sizes in addition to model sizes.
- Demonstrate that using spectral P perspective eliminates a particular failure case in the standard method of validating a P implementation: coordinate checking.
A Brief History of P
The seminal paper in the study of P is the Tensor Programs V paper (TP-V) (Yang et al. 2022) which presented the successful application of Tensor Programs to improving real-world training dynamics. We briefly note that this is the fifth paper in what is generally considered a six to ten paper series (depending on how you’re counting). We will not focus on the first four papers in this blog (Yang 2019) (Yang 2020a) (Yang 2020b) (Yang & Hu 2020), but emphasize that the -transfer theory posed in TP-V crucially builds on Yang’s previously developed theory. The original TP-V paper addresses learning rate transfer across width, and we discuss extensions and attempted extensions of this work below.
It’s been three years since the TP-V paper, and the community has explored improvements in understanding of P as well as validation of P up to the 13B scale (Dey et al. 2023). Anecdotal rumors are that several of the large frontier labs are using P at much larger scales than this.
In terms of theoretical developments we choose to emphasize the “spectral P” paper written by Yang, Simons, and Bernstein (Yang et al. 2023b) which re-formulates P in terms of spectral weight norms. We will discuss this theoretical perspective in much greater detail below. Yang’s group also attempted to apply P to the case of depth (Yang et al. 2023a) (TP-VI), but was only able to get successful feature learning with residual blocks consisting of a single linear weight matrix and as such does not apply to the practical case of training LLMs. Finally, practitioners should be aware of the Complete-P paper (Dey et al. 2025), which primarily addresses the deficiencies in the TP-VI paper and derives the correct P parameterization for depth. We consider this paper to be the current state of the art for applying P in practice. The authors additionally derive scalings for other aspects of LLM training which were left out from the original P papers. We suggest that the Complete-P paper be used as a reference for implementing P since they have the most comprehensive table of parameter scalings.
More recently our own group has extended the P theory to cover the challenging case of grouped query attention (GQA) which required some subtle extensions to the overall theory (Chickering et al. 2025).
Finally, as this blog post was being finished, Soufiane Hayou released the first actual mathematical proof that learning rate transfers under P (Hayou 2025). This exciting new work finally bridges the gap between the theoretical intuitions of TP-V and a rigorous theory of learning rate transfer.
Spectral P
The Tensor Programs V paper proposes a method for zero-shot hyperparameter tuning by carefully applying the analysis from Tensor Programs to determine the proper learning rate and initialization schemes for a neural network (Yang et al. 2022). To this end the authors define the concept of feature learning. Let be the activations of the -th layer of the neural network at timestep , and let . If the output of the -th layer is , we say that feature learning is occurring for the layer if
as . The authors show that for a network satisfying feature learning at every layer we should (with some caveats) expect that the learning rate transfers across models of different width . In other words, we can sweep hyperparameters (learning rate) at some and use those same hyperparameters (learning rate) for a model with .
The theory is called maximal (as in maximal update parameterization) because if the layer updates were any smaller (asymptotically) we would learn very slowly, but if they were any bigger the training would diverge. Thus, this scaling is precisely the fastest we can update our weights without the training diverging.
While groundbreaking, P and an intuitive understanding of feature learning remained challenging after the publication of TP-V. In a follow-up work, Yang, Simons, and Bernstein provide a more mathematically satisfying explanation and intuition for feature learning, phrased in terms of the weights of a neural network instead of the activations (Yang et al. 2023b). This viewpoint is preferable for several reasons:
- The adjustments to the neural network are done through the weights, not through the activations, so a theory based purely on the network weights allows more direct access to quantities we are scaling / adjusting; it is easier to have a theory based directly on than based tangentially through .
- The update maximality becomes quite obvious, rather than being obscured behind a matrix-vector product. Practically speaking, using the spectral theory rather than the original theory allows us to avoid some subtle failures in the original conception of P: we show that the spectral conditions are more stringent than the original conception.
- In terms of norms on the weights we get a better intuition of what conditions about the network lead to learning rate transfer. It is arguable that this viewpoint helped lead to the development of the Muon optimizer (Jordan et al. 2024).
In particular, Yang et al. prove that conditions on the spectral norm of the weight matrices (see equation below) imply that feature learning in the sense of equation holds.
To follow their argument we consider a dense MLP network with input dimension , output dimension , and hidden dimension . We consider the case where both and are fixed but we scale the hidden dimension . This setting can be mapped to transformer LLMs and conv-nets with little to no modification, but we choose this simple setting for pedagogical purposes. We then set for the input layer, and for the hidden and output layers, as well as for the input and hidden layers, and for the output layer.
Under this notation, (Yang et al. 2023b) prove that the weights of layer at timestep , given by , and the updates , should satisfy the following constraints on their spectral norm
Recall that the spectral norm, or induced 2-norm, is given by
In what follows we dispense with full rigor and focus on the essence of the mathematical argument. However we stress that the statements made here can be made fully rigorous, and indeed this is done in (Yang et al. 2023b).
Informally, during neural network training we have the relationship
from which the implication that becomes quite clear if we ignore the activation function, since we have assumed recursively that the inputs satisfy the feature learning condition .
Spectral P is Stronger than Feature Learning
The reverse implication is not true. Feature learning in the sense of condition does not imply that the spectral feature learning condition is met.
Consider a weight matrix with weight update . Assume that the , but that for some . Further assume that the inputs to this layer satisfy feature learning, that is . Ignoring the non-linearity, it is clear that this weight matrix does not satisfy the conditions of spectral P. However, note that
so the output of the layer scaling satisfies feature learning in the sense of . Furthermore
and the updates also satisfy . Thus, feature learning is occurring despite the fact that the spectral conditions are not satisfied!
The reason for this failure should be quite clear: If a weight matrix is sub-maximally updated (in this case ), then the correct scaling from the previous layer is propagated to the current layer purely through the initialized weights . This can be taken to the extreme case by setting the weight updates identically to zero, and we see that feature learning in the sense of continues to occur (see below for an empirical demonstration of this fact).
This is an important distinction because the impetus for P is to be maximally training the network. Quite literally we would like the weight updates specifically to be updated as maximally as possible. However this criteria is not actually enforced by condition , even though this is the philosophical motivation for a feature learning condition like . Thus, we suggest that the spectral feature learning condition is the “correct” perspective for maximal update parameterizations, and that this stronger conception of feature learning should be the basis for theory moving forwards.
A Misconception about P and Time
We briefly address a common misconception that we have encountered when discussing P. Many readers have read TP-V and come away with the conclusion that P makes predictions on the size of network activations through time. However this is manifestly not the case.
Consider the more detailed notation , where is some function depending on the parameters . The notation means that we have the inequality
where are constants (in ) and the inequality is expected to hold for all in some unbounded subset of .
Specifically for P, we make statements about the spectral norm of the form , and notably we do not make statements of the form . Thus, when we say that , this simply means that as we scale , the hidden size, we must have
All that P says about the upper and lower bounds in time is that the bounds cannot depend on the network width, for sufficiently large networks. In other words, there exist width dependent upper and lower bounds, but absolute upper and lower bounds in time, with respect to width:
Coordinate checking across time will not necessarily show constant behavior as it does when we coordinate check across network width.
A Heuristic Toolkit
While the mathematics underlying P may be both deep and complicated, we have found in practice that deriving P for new architectures requires insight into neither Tensor Programs nor random matrix theory. Rather, P derivations can typically be done using a few simple heuristics (which are, of course, ultimately derived from Tensor Programs and random matrix theory!). We present these heuristics which can be used to understand the observed dynamics of neural network training and allow practitioners to derive novel P scalings.
At a high-level, what we will do is assume that the spectral feature learning conditions ensure hyperparameter transfer, and then systematically examine the weight matrices in the network and make sure that they satisfy these conditions.
In what follows we will use the notion of “typical size” which is used by Yang and is common in the random matrix theory literature (Tao 2012). Readers may instead know this quantity as the first absolute moment and it is given by
with denoting that is of typical size . This is used to understand what we expect the entires of a random matrix to look like, and is commonly used to heuristically estimate norms of a matrix or vector. As an example computation, consider a random vector with typical size . We can apply the law of large numbers (LLN) to heuristically estimate
With these preliminaries dispensed with we now introduce our heuristics which we can use to derive P in a variety of settings. Our first heuristic regards the scaling of the model gradient as a function of the layer width:
Heuristic 1: Gradients
Gradients scale like
Doing our analysis in terms of the spectral norm allows us to use standard theorems from random matrix theory to understand how the size of the weight matrices changes as a function of their input shapes. In particular we can use the Bai-Yin theorem (Bai & Yin 1993) (Yin et al. 1988) which tells us how the spectral norm of a rectangular random matrix scales. We note that there are some additional caveats to applying Bai-Yin, but all of them are satisfied in practice during neural network training:
Heuristic 2: Bai-Yin Theorem
Let with entries sampled i.i.d. from , then we have
In particular, as and grow large we have
If is instead sampled from a distribution with non-zero mean then we have
Finally, while the internal representations of a neural network do not actually look i.i.d. Gaussian, we have found that treating them as if they are i.i.d. Gaussian is a productive way to derive P:
Heuristic 3: Playing pretend
P scalings can be derived by assuming that are sampled i.i.d. from a Gaussian distribution. Furthermore we can always assume that the previous layer quantities and are i.i.d. sampled from a Gaussian.
Heuristic 3 is certainly not rigorous, in fact it isn’t actually even true! But we find in practice that to derive the first order scalings of the weight spectral norms this assumption is sufficient to capture the actual training dynamics.
Example Derivations
Network Initialization
The network initialization can be directly read off of equation together with Heuristic 2 (the Bai-Yin theorem), since for a weight matrix
Solving for the standard deviation gives
If we carefully track which of the dimensions is being scaled, then we arrive at the standard P initialization rule:
SGD
Stochastic gradient descent is the easiest optimizer to study. We simply update the weights according to
where is the learning rate hyperparameter. According to the spectral condition , this then implies that we must have
Determining the correct scaling for the per-layer learning rates is then reduced to understanding how the gradient scales in spectral norm. From Heuristic 1 we know how the individual elements of the gradient scale, and thus we compute that
Thus, we can use the spectral feature learning condition to read off the learning rate scalings
Adam
The Adam optimizer (Kingma & Ba 2014) builds on SGD by tracking the first and second moments of the gradients over time
and then the weight update is given by
How large are the Adam optimizer steps ? From Heuristic 1 we know how the gradients scale, and thus
due to the linearity of addition. Similarly, the typical size of the Hadamard product of the gradient has the typical size
In particular we then expect that the typical size of the is
Technically we can be more precise and determine exactly how small must be to get consistent training dynamics. This scaling was first observed in the literature seemingly independently by (Dey et al. 2025) and (Everett et al. 2024). Let and , where captures the heterogeneity of the gradient scaling between layers. After some algebra we arrive at the informal scaling
This implies that for transferable dynamics to continue, we must induce a dependence so that . We find in practice that for small-scale experimentation that setting small (say ) suffices to have transferable dynamics without adjusting the Adam parameter. However for large-scale runs and may shift significantly in time and violate the P hypotheses in practice.
Because we know the typical size of the Adam update steps is , we can apply Heuristic 2 to understand that if the weights have shape then the spectral norm is simply . Then applying the spectral feature learning conditions we have
AdamW
AdamW builds on the the Adam optimizer by additionally adding a weight decay term with decay strength (Loshchilov & Hutter 2017). The Adam weight update is then replaced by
which adds dynamical pressure to return the weights to the origin at every step. To ensure that these updates retain their correct size in the spectral norm we must have that .
To see why, suppose that for , then in the limit that our update rule collapses to the original Adam update and we retain no benefit from using weight decay. On the other hand, if , then for sufficiently large our update rule is
and our training will cease to be dependent on the data. I.e. meaningful learning becomes impossible.
These considerations together with the Adam learning rate scaling lead us to conclude that for the weight decay update described in we should scale the weight decay according to
Depth and Complete-P
The spectral P framework can also be extended to derive the corrected depth scalings arrived at in Complete-P through the addition of an extraneous desiderata. We argue that the depth scaling from TP-VI is wrong because their updates are too small in norm. We show that depth-P does not satisfy the spectral feature learning conditions, and furthermore that assuming the spectral feature learning conditions prevents lazy-learning (Dey et al. 2025).
Thus, we are able to arrive at the correct Complete-P (Dey et al. 2025) scaling without adding additional desiderata, using only the spectral feature learning conditions.
For our setting we consider the residual blocks of a depth network given by
for a residual block with parameters , usually an MLP block. Of course, to study the operator norms we can write this computation as
so that . Making standard assumptions about composition and lack of cancellation we have
Recursing this identity gives us the spectral bound
In order for the network outputs to remain stable at initialization, we require that the summation through the entirety of the network at initialization scales correctly, that is
in both and , where is the hidden size. For typical MLP implementations it is sensible to require that , in which case we must have that to keep the correct scaling. However this is not the only available way to parameterize depth (see below). Note that for any (Yang et al. 2023a) prove that the parameterization is trivial (in the limit the network converges to the identity). Another way to think about this is that for non-trivial learning to occur we must have the contributions from the residual branch and the MLP branch be the same asymptotic size at the output of the network.
Depth P Doesn’t Satisfy Spectral Feature Learning
Our first observation is that the proposed depth-P framework from TP-VI does not satisfy the spectral feature learning conditions . The authors of TP-VI consider MLP blocks , with . Our argument will also apply to rectangular matrices, but we choose square matrices here for the ease of exposition. Depth-P suggests initializing the hidden layers from , but setting the learning rate to be . Thus we have
In this case as , the weight updates are too small to learn meaningful features, our updates are no longer maximal! Note that we will still pass a coordinate check in this situation because of the failure case described by equation (see also the empirical coordinate check failures discussed below), further providing evidence for the superiority of the spectral perspective.
Spectral P Prevents Lazy-Learning
The Complete-P depth parameterization is motivated by the following observation: even though feature learning is occurring in the sense of , the model weights get “stuck” in the “lazy-regime”, severely harming performance. From the spectral P perspective, it is clear why this is happening: with the sub-maximal updates we barely move away from the initialized weights.
Roughly speaking, lazy-learning occurs for a layer we have
where
Under this framework we are saying that lazy-learning occurs if the linearization around the initial weights is a good approximation as we scale . But this is precisely what spectral feature learning aims to prevent!
Observe that by Taylor expansion we simply have
in other words
Note that if we enforce the spectral feature learning conditions then this term is never , but for depth-P the right hand side decays like and thus exhibits lazy-learning whenever .
In summary, using spectral P as the basis for our theory means that we do not need the additional Desiderata from the Complete-P paper to derive Complete-P, simplifying the theoretical analysis.
An ABC-Type Family of Depth Parameterizations
The failure of depth P is caused by the weight updates being the wrong size for the initialization, but this leaves open the possibility of shrinking the initialization to match the size of the weight updates. Sample so that
to match the weight updates. We now have
as desired. It remains to be seen whether or not this parameterization actually leads to feature learning and -transfer in practice. There is reason to suspect it may not, chiefly that having the weights and weight updates shrinking so severely as we scale depth seems undesirable. We leave further theoretical and empirical investigations of this depth parameterization to future work.
Muon
Muon is a recently introduced optimizer (Jordan et al. 2024) which has shown promising results for training LLMs at scale (Liu et al. 2025) (Bai et al. 2025).
The Muon update rule is given by
where is the approximately orthogonalized gradient with respect to , found using a Newton-Schultz iteration scheme (Jordan et al. 2024). From the perspective of spectral P what we primarily care about is the size of the spectral norm of , which is by construction (Bernstein 2025). This implies that the learning rate for the hidden layers in a neural network using Muon should scale like . Learning rate should transfer without having to adjust the initialization scheme or the learning rate (Assuming that we are using Adam under SP for the initialization and output layers).
Muon is typically applied with decoupled weight decay and the full weight update rule
Note that our analysis from above continues to hold, except now that the learning rate is for hidden layers, the weight decay will also be . Not only does Muon fix the learning rate scale, but it also fixes the weight decay scale when using decoupled weight decay.
Does Muon Kill P
As authors and teams have demonstrated the effectiveness of using MuON at scale the usefulness of P as a discipline have been called into question. However, we argue here that this may be a distinction without a difference, since the principles of P remain relevant, even when one uses Muon.
For example, Muon won’t transfer learning rate by default on GQA, and the reasons are the same as the reasons outlined in (Chickering et al. 2025). Namely that the spectral norm and the expected operator norm of the network computation do not agree. Thus, getting Muon to work in this setting requires the same fundamental understanding of the underlying behavior of the computation in the spectral norm. Whether or not doing this analysis constitutes “P for Muon” is up for debate, and frankly the distinction is somewhat meaningless. Regardless, we believe that much in the same way students are encouraged to study SGD before moving on to studying Adam, so should practitioners be encouraged to understand P prior to moving on to Muon.
Finally, we note that as of this writing, efficient, large-scale, open-source Muon implementations are lacking. Because of this there may be a period of time where Adam continues to be the preferred method of training models. Furthermore, the practical benefits of large-scale training with Muon are not fully understood. It may be the case that the benefits of training with Muon vanish for very large training runs (Wen et al. 2025). It is challenging to ablate a large-scale LLM training run, which makes committing to using Muon challenging. However, we stress that an understanding of the strengths and weaknesses of Muon is currently lacking, but we will likely understand this optimizer better in the coming months and years.
The Implied Dynamics of P
We pause to consider the implications of not using P. In particular we argue that we should understand this situation as representing different layers learning at the incorrect rate. We also argue why we see the standard-parameterization scaling heuristics that we do.
Given that most neural network training already initializes the weights using Kaiming-He, which is correct from the perspective of both standard and spectral P, the deficiency in using the standard parameterization must be understood exclusively throughout the weight update scalings. We consider the common case of the Adam optimizer and can then understand the issues with the standard parameterization by considering the proposed P modification to the learning rates which derived above in .
These scalings imply that during training with the standard parameterization, the embedding layer will be learning times slower than the hidden layers and unembedding layers (this is complicated by weight tying, which we ignore in this blog). Assuming that we tune the training to find an optimal learning rate, we expect to find an empirical law , since the majority of layers in a network are hidden layers, which naturally prefer this scaling. However, training at this reduced learning rate will severely degrade the rate at which the embedding layers are updating, leading to the majority of training taking place with essentially frozen and essentially random embedding weights!
This is a potential cause of issues during pre-training, especially as the model sizes get large: the embedding layer is essentially frozen at it’s random initialization, and the model does not learn embedding features quickly enough to send meaningful signal to the lowest layers attention blocks. Worse, the embedding component of the transformer loss contributes noise to the gradient, slowing down the rate at which we can train models at all. As we decrease the learning rate further to compensate for this discrepancy, we exacerbate the frozen input weights, leading to a situation where the model’s capacity is reduced. This is why in the TP-V paper we see improved loss when using P instead of SP for the largest models: as in SP, the embedding weights become frozen to their random initialized weights, effectively reducing the model capacity. P allows us to fully utilize the model’s capacity during training.
Transferring Across Weight Decay, Learning Rate, and Batch Size
The original TP5 paper (Yang et al. 2022) suggests that we should not expect learning rate transfer across weight decay or batch size. While we do not offer a conclusive rebuttal to this assertion, but we consider some more recent work which has made strides in articulating the problem more thoroughly.
We follow a line of work originating with (Wang & Aitchison 2024) and explored in more depth by (Bergsma et al. 2025). In particular, Wang & Aitchison suggest that weight decay and learning rate should be related through the quantity
where is the batch size and is the dataset size. They suggest that this quantity should transfer across model training (implicitly this transfer is understood only to occur at the optimal learning rate) and this suggestion is based off of a discrete dynamics argument focused on the the change in the weights induced by the total integrated weight decay during training.
We emphasize an important point which we feel is not sufficiently stated in the existing literature: we should only expect that is transferable at the optimal learning rate. The reason should be clear: for a fixed dataset and batch size there are two limiting cases for the weight decay and learning rate. In the first case, as , learning will not happen since the learning dynamics will be governed purely by the exponential decay of the weights. In the other limiting case, and , in which case the dynamics will be too unstable to meaningfully discuss training.
In the figure below we demonstrate that properly scaled decoupled weight decay and both exhibit transferability when maintaining a constant TPP and using an empirical scaling law for batch size (see Figures below).
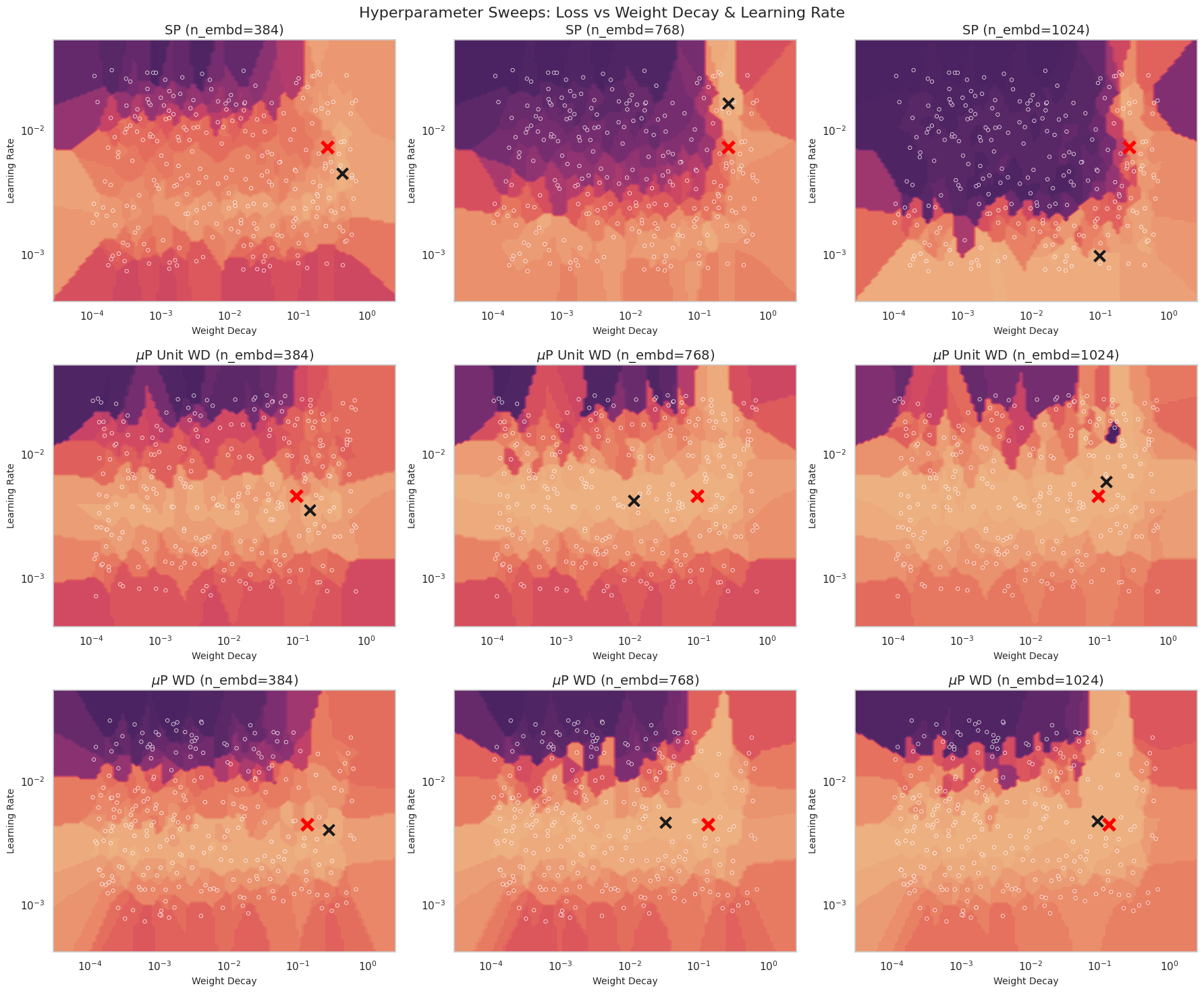
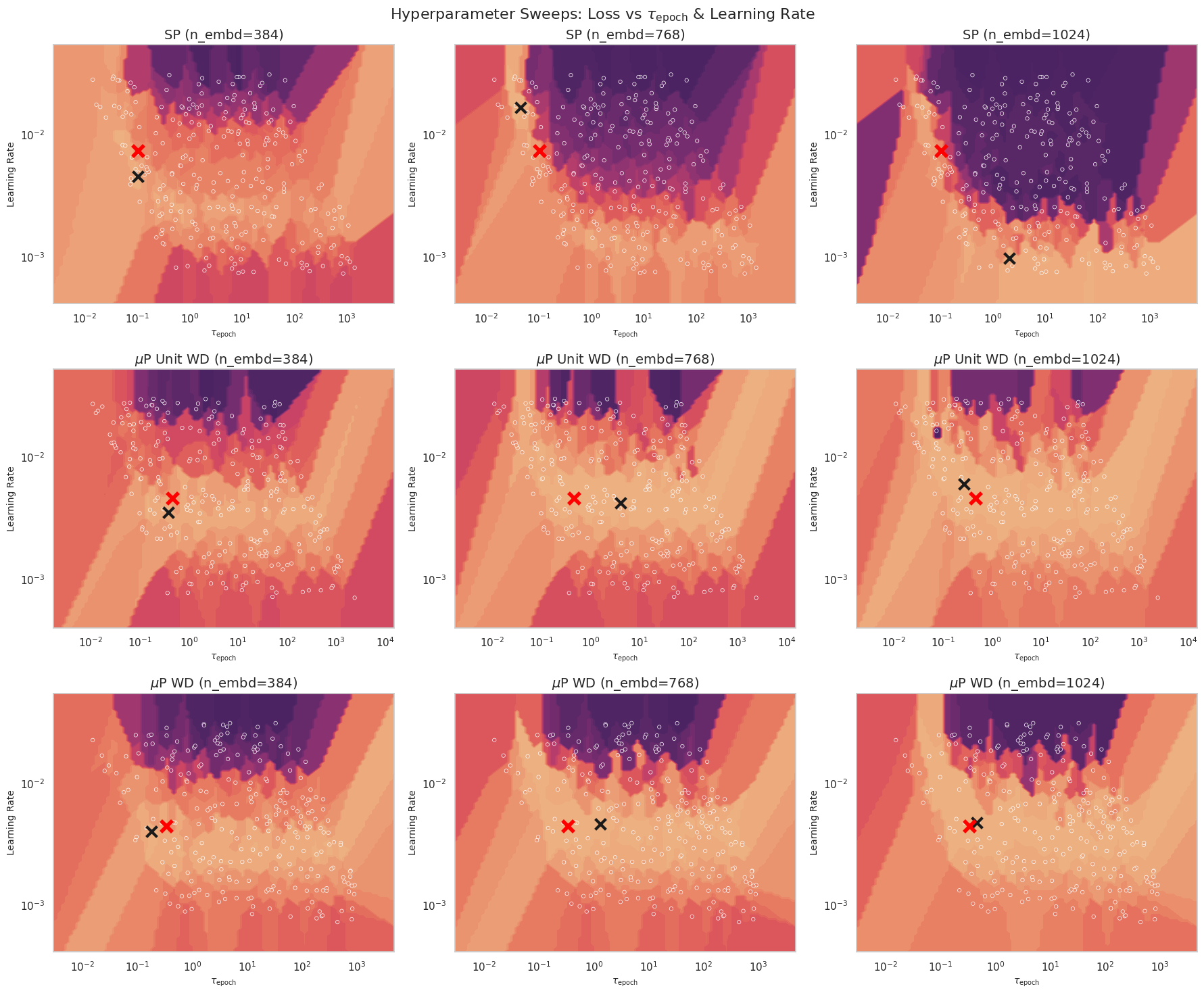
Finally we argue that for a fixed maximum model size we can transfer learning rate across batch size and model size using P so long as the batch size is sufficiently large and we allow ourselves to scale the dataset size. I.e. we are in the infinite data regime.
The figure below shows the relationship between loss, learning rate, and batch size in the constant TPP (constant data) and constant iterations (infinite data) regimes.
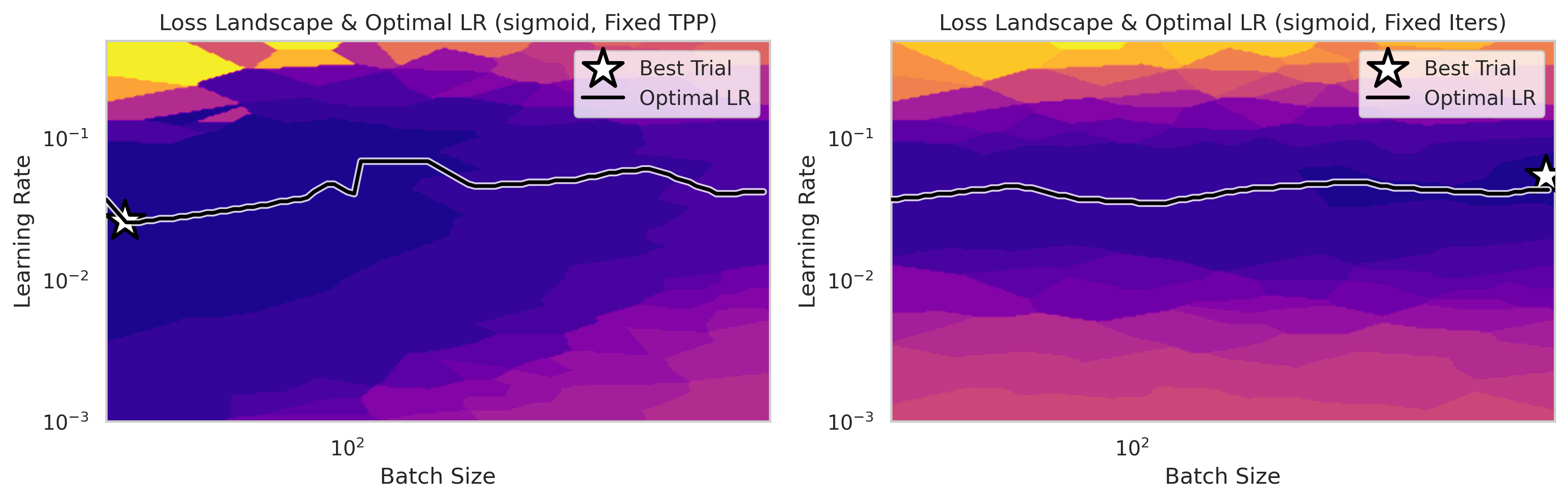
The infinite data regime is obviously unrealistic for any practical training, but it offers us an ablative setting for small model experimentation with architectural considerations like P. To test modifications to P we can use a sufficiently large batch size to isolate the effects of the model architecture, compared to the effects of the substrate (dataset and batch size). Once we are sure that our P implementation is working as we expect we can move on to finding and tuning in the compute optimal setting.
Some Pitfalls of Coordinate Checking
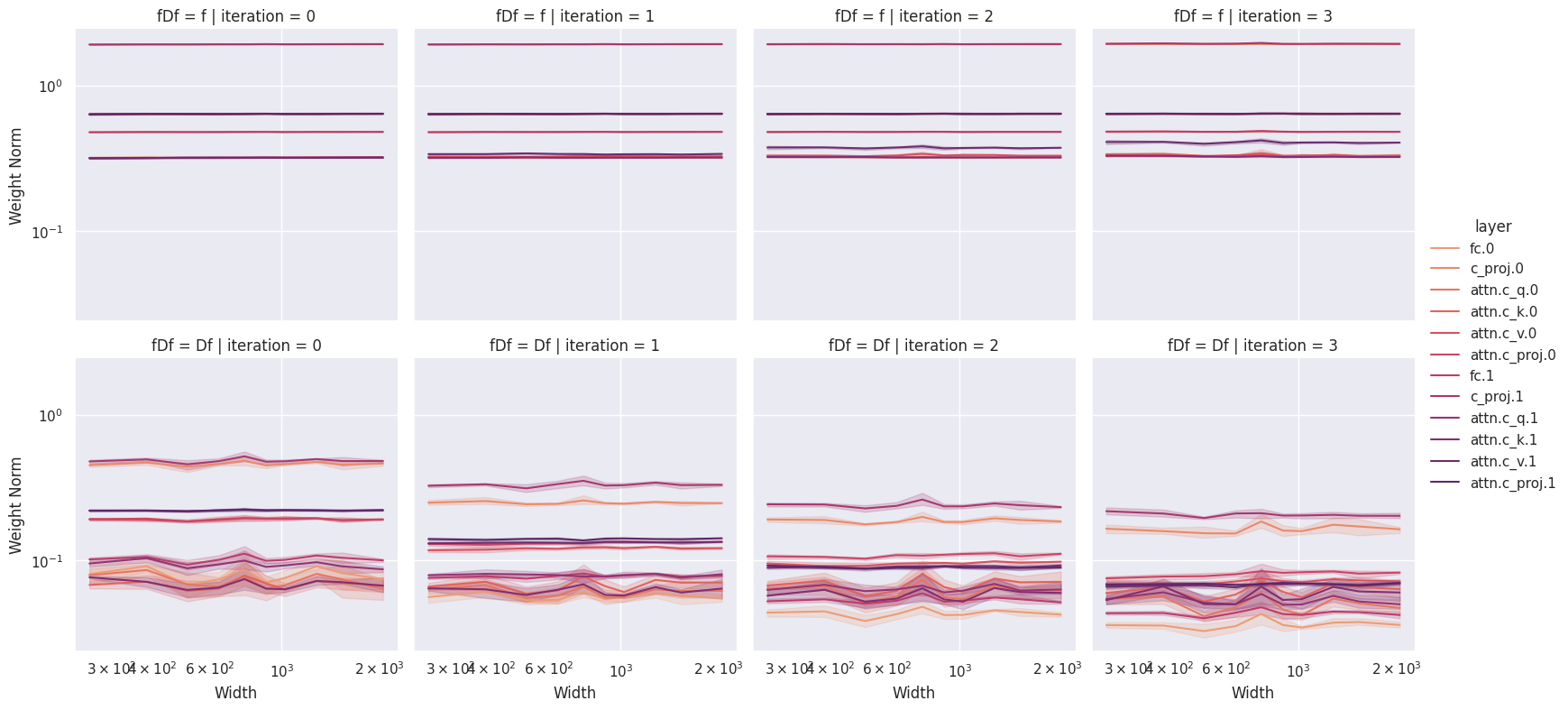
In this section we summarize some of the pitfalls we have encountered when performing coordinate checking. Before moving forward we discuss some intuitions for practitioners new to coordinate checking. Below we plot a “clean” coordinate check, and note that the coordinates appear stable as we scale model size, with the weights themselves (top row) showing lower variance than the weight updates (bottom row). The first figure shows a standard coordinate check on the activations.
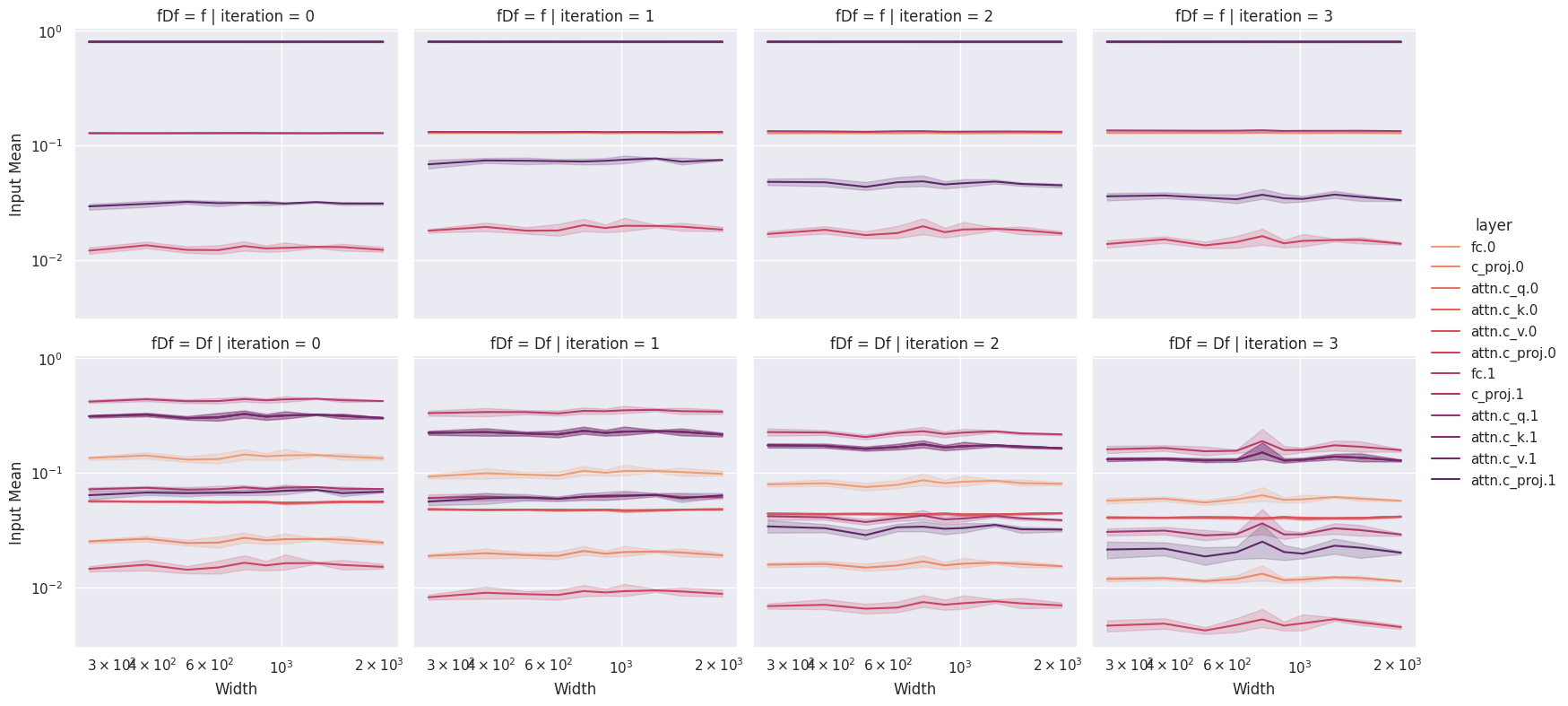
A general intuition is that the updates appear to deviate from the “flat” as training progresses, while the spectral coordinate checks get more stable as training progresses. This is easily understood as a consequence of the fact that is a sum of two products (see above) and as such does not directly measure the weight updates.
A Failure Case: Sub-Maximal Interior Layer Weight Updates
Building off the computations from the previous section on spectral P, we show that the failure case described above, namely the weight updates of an interior hidden layer being too small, will not show up in a (Yang et al. 2022)-style coordinate check.
To be more specific, since we can write
both terms will contribute to the output size. Since our recursion assumes that both and are the correct size, this means that if we set the weight updates to zero, i.e. , then we have , but this is actually correct in norm, since
The layer is passing coordinate checks, but the layer is constant, there is no learning going on, and this represents a bug in our implementation.
The following figure demonstrates the issue. We run a coordinate check on a GPT-2 style LLM, using a P implementation with the hidden layer learning rate set to zero. Thus, the hidden layer weights are constant . Despite this, our model has a (mostly) clean coordinate check.

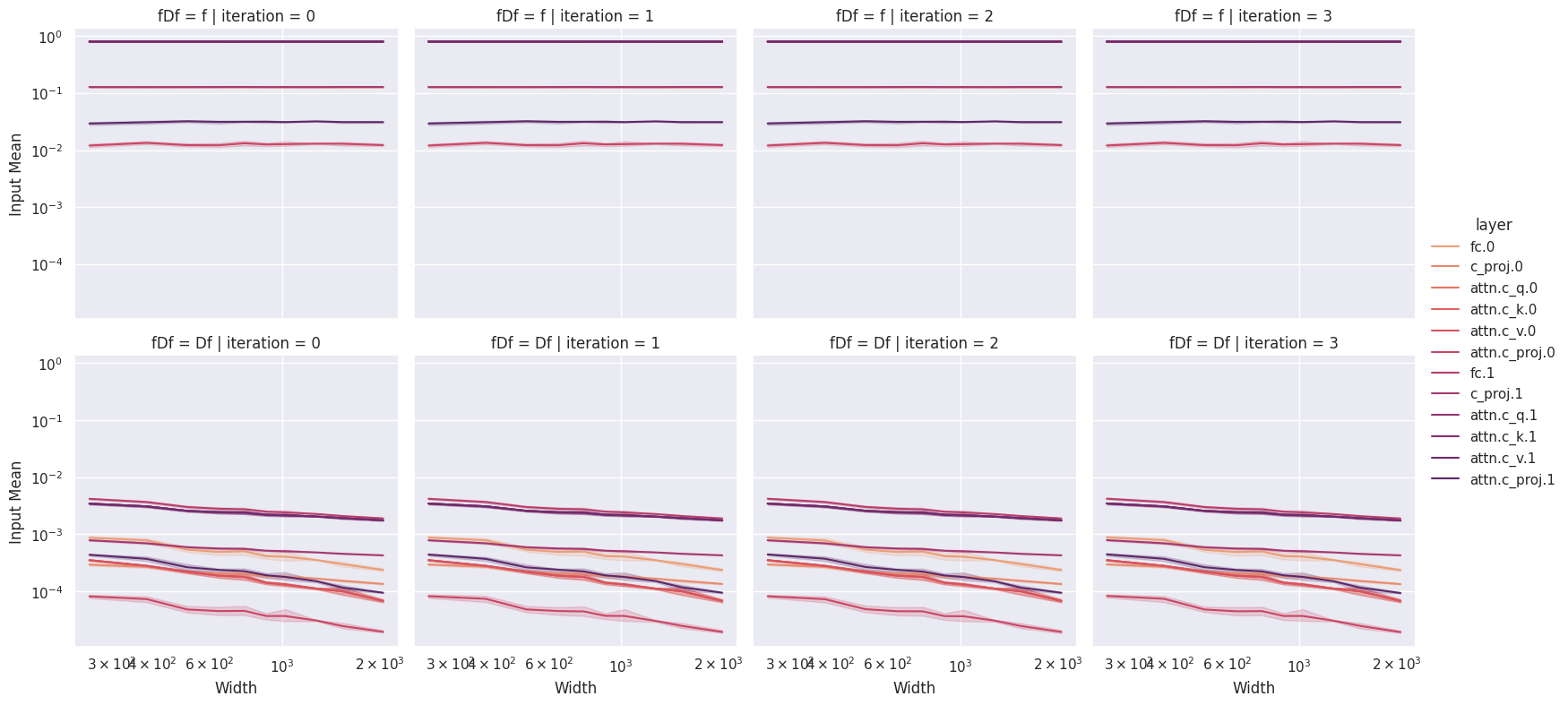
If we follow the suggestions of TP-V, then we would conclude that this implementation is correct. However, our implementation does not pass the more stringent spectral coordinate checks which we advocate for. Below is the spectral coordinate check for the same model where we can clearly see that no learning is occurring.
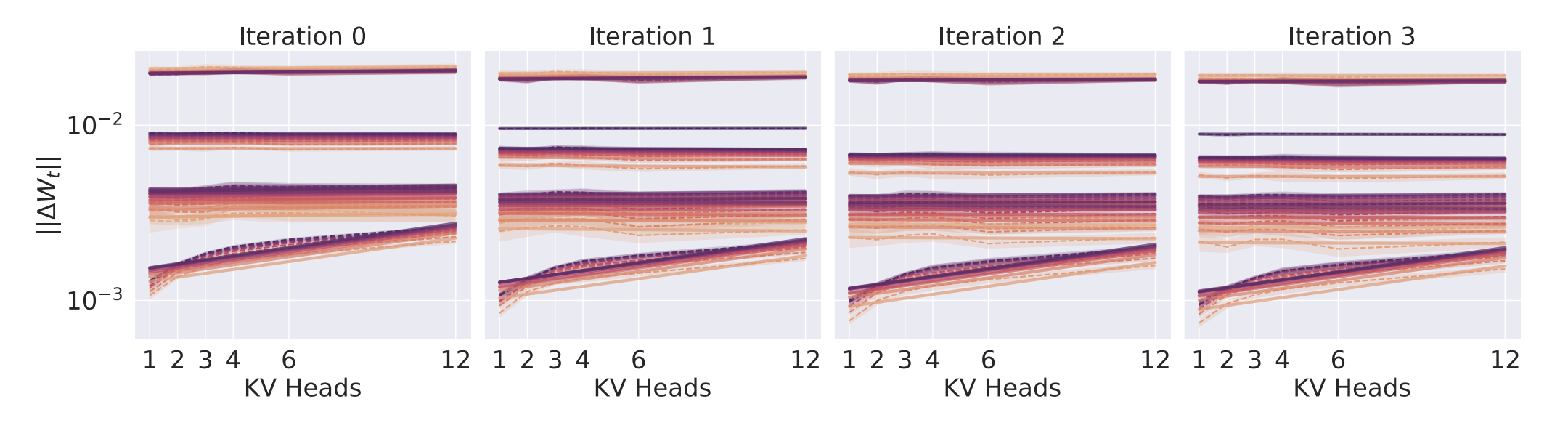
The following figures are taken from our recent paper (Chickering et al. 2025). When applying P to grouped-query attention (GQA), one finds that the naïve approach passes a standard coordinate check (first figure), but fails a spectral coordinate check (second figure) and will not produce robust learning rate transfer. We addressed this issue by performing the analysis in the spectral norm rather than the activation 2-norm. This particular failure case further highlights the “correctness” of the spectral perspective.

A Failure Case: Non-Power Law Scalings & Power Laws with Questionable Exponents
In the course of our experiments we encountered a second subtle case of failing coordinate checks. This case involves a coordinate check with a non-power law scaling and usually indicates that there is a subtle implementation bug somewhere in the system. Concretely we can force this bug to show up in two places (1) when using the Adam optimizer with the parameter set to be too large, and (2) when looking at a mixture-of-experts router with a poorly tuned load balancing loss.
The following figure shows a coordinate check where the hidden layers are being sub-maximally updated due to the Adam parameter being set too high. In this case the updates behave roughly like the first moment, which decays as the hidden size increases according to Heuristic 1. The decay in weight updates leads to a shift in learning rate during -transfer.
Conclusions
If we can leave the reader with a single takeaway it is that for any large-scale training runs teams should use some combination of P and Muon to ensure that all of the layers are training at the “correct” rate. Beyond that, when working with P implementations one should favor a spectral norm perspective to an activation norm perspective to avoid some subtle pitfalls that can occur when working with P.
References
- (Bai & Yin 1993)
Bai, Z. D., Yin, Y. Q. Limit of the Smallest Eigenvalue of a Large Dimensional Sample Covariance Matrix. Ann. Probab. 1993.
- (Bai et al. 2025)
Kimi Team. Kimi K2: Open Agentic Intelligence. arXiv. 2025.
- (Bergsma et al. 2025)
Bergsma, S., Dey, N., Gosal, G., Gray, G., Soboleva, D., Hestness, J. Power Lines: Scaling Laws for Weight Decay and Batch Size in LLM Pre-training. NeurIPS (to appear). 2026.
- (Bernstein 2025)
Bernstein, J. Deriving Muon. 2025.
- (Chickering et al. 2025)
Chickering, K. R., Wang, H., Wu, M., Moreno, A., Chen, M., Ma, X., Soboleva, D., Hestness, J., Liu, Z., Xing, E. P. GQA-P: Maximal Update Parameterizations for Grouped Query Attention. Submitted. 2025.
- (Dey et al. 2023)
Dey, N., Gosal, G., Chen, Z., Khachane, H., Marshall, W., Pathria, R., Tom, M., Hestness, J. Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster. arXiv. 2023.
- (Dey et al. 2024)
Dey, N., Anthony, Q., Hestness, J. The Practitioner’s guide to the maximal update parameterization. Cerebras Blog. 2024.
- (Dey et al. 2025)
Dey, N., Zhang, B. C., Noci, L., Li, M., Bordelon, B., Bergsma, S., Pehlevan, C., Hanin, B., Hestness, J. Don’t be lazy: CompleteP enables compute-efficient deep transformers. NeurIPS. 2025.
- (Everett et al. 2024)
Everett, K., Xiao, L., Wortsman, M., Alemi, A. A., Novak, R., Liu, P. J., Gur, I., Sohl-Dickstein, J., Kaelbling, L. P., Lee, J., Pennington, J. Scaling Exponents Across Parameterizations and Optimizers. arXiv. 2024.
- (Hayou 2025)
Hayou, S. A Proof of Learning Rate Transfer Under P. arXiv. 2025.
- (Jordan et al. 2024)
Jordan, K., Jin, Y., Boza, V., You, J., Cesista, F., Newhouse, L., Bernstein, J. Muon: An optimizer for hidden layers in neural networks. Keller Jordan Blog. 2024.
- (Kingma & Ba 2014)
Kingma, P. D., Ba, J. Adam: A Method for Stochastic Optimization. arXiv. 2014.
- (Liu et al. 2025)
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, Zhilin Yang. Muon is Scalable for LLM Training. arXiv. 2025.
- (Loshchilov & Hutter 2017)
Loshchilov, I., Hutter, F. Decoupled Weight Decay Regularization. arXiv. 2017.
- (Tao 2012)
Tao, T. Topics in Random Matrix Theory. AMS GSM. 2012.
- (Wang & Aitchison 2024)
Wang, X., Aitchison, L. How to set AdamW’s weight decay as you scale model and dataset size. arXiv. 2024.
- (Wen et al. 2025)
Wen, K., Hall, D., Ma, T., Liang, P. Fantastic Pretraining Optimizers and Where to Find Them. arXiv. 2025.
- (Yang 2019)
Yang G. Tensor Programs I: Wide Feedforward or Recurrent Neural Networks of Any Architecture are Gaussian Processes. arXiv. 2019.
- (Yang 2020a)
Yang G. Tensor Programs II: Neural Tangent Kernel for Any Architecture. arXiv. 2020.
- (Yang 2020b)
Yang, G. Tensor Programs III: Neural Matrix Laws. arXiv. 2020.
- (Yang & Hu 2020)
Yang, G., Hu, E. Feature Learning In Infinite-Width Neural Networks. arXiv. 2020.
- (Yang et al. 2022)
Yang, G., Hu, E. J., Babuschkin, I., Sidor, S., Liu, X., Farhi, D., Ryder, N., Pachocki, J., Chen, W., Gao, J. Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer. arXiv. 2022.
- (Yang et al. 2023a)
Yang, G., Yu, D., Zhu, C., Hayou, S. Tensor Programs VI: Feature Learning in Infinite-Depth Neural Networks. arXiv. 2023.
- (Yang et al. 2023b)
Yang, G., Simon, J. B., Bernstein, J. A Spectral Condition for Feature Learning. arXiv. 2023.
- (Yin et al. 1988)
Yin, Y. Q., Bai, Z. D., Krishnaiah, P. R. On the limit of the largest eigenvalue of the large dimensional sample covariance matrix. Probability Theory and Related Fields. 1988.
Citation
@misc{chickering2025mup,
author={Kyle R. Chickering},
title={The Spectral Maximal Update Parameterization in Theory and Practice},
year={2025},
url={},
publisher={Kyle Chickering's Blog}
}